Last night, I completed the transition from Wordpress to Drupal. Why? Well just try and look at the code. Drupal is the cleanest PHP implementation I’ve ever seen, and Wordpress is like most of the other PHP apps I’ve seen. Yet another reason I love my linode - I was able to build my new VM at home, then upload it to my host. Total downtime was about 5 minutes, and I am now running on a completely new partition built from scratch. Anyways, I’m sure there will be plenty of kinks to work out, but it looks like most of the stuff is working. Drop me a comment if you find something out of whack. Stay tuned for a post on how to “take your linode image home with you”.
Disable SNMP Printer Scanning in Ubuntu Intrepid
After installing Ubuntu Intrepid on my laptop, I got a nastygram from IT saying that my laptop was tripping alerts from their NIDS. They could tell me that it was an outbound SNMP request, but they couldn’t supply the OID or anything. Setting aside the fact that the NIDS should be configured to disregard SNMP requests for this particular OID, I set forth to try and figure out what the heck was causing the traffic. After much tcpdumping, I finally found the OID: 1.3.6.1.2.1.25.3.2.1.3.1. Googling told me that this OID corresponds to a printer name. At this point, I knew that it was coming from CUPS. Now, one would think that there is a simple on/off switch in CUPS that you could use to disable SNMP scanning. Nope! You can remove the snmp binary from the CUPS distribution, but the next time CUPS is installed/upgraded, you’ll be in the same boat. On a hunch, I edited /etc/cups/snmp.conf to look like so: #Address @LOCAL Address 127.0.0.1
Lo and behold, it worked! Instead of disabling SNMP scanning, I told CUPS to only scan the localhost IP instead of the entire local LAN subnet. After applying this change and restarting CUPS, I checked with IT. The NIDS alerts had indeed stopped generating alerts! Notes It turns out the snmp auto-detection stuff had been removed from previous versions of Ubuntu. After much bemoaning from users, the package maintainers put it back in place. This is why I have the issue on Intrepid and not on previous versions. I don’t really know what the optimal solution is here. The fact that my laptop was broadcasting SNMP requests to the entire corporate subnet is a little disturbing, if harmless. However I see where it would be nice to have in a SOHO environment. I personally would prefer a “disabled by default” approach with a very simple checkbox mechanism to enable it, but I’m certainly biased. Anyways, hope this helps some people out there. When I ran into this issue, Google didn’t have any help for me.
Profile Your Java GC Performance With GChisto
I stumbled across GChisto the other day when
looking for some garbage collection analysis tools for Java. Anyone who’s
tried tuning Java GC (especially on older JVM’s) knows that it’s about as much
fun as watching paint dry. However, many times you can seriously improve
performance by taking the time to analyze what your GC’s are doing. GChisto
attempts to give you a birds-eye graphical view of your GC operations, and has
a very handy comparison feature that allows you to compare the differences
between GC logs. A picture is worth a thousand words, so here’s a teaser:
Installation of GChisto
These instructions are tailored for Ubuntu, but should work for any distro. As long as you can do CVS on Windows, these instructions apply there as well. Also note that this overview is focusing only on how GChisto works with GC logs generated by the CMS collector. It works with all types, but the CMS type is all that is covered here. To run GChisto, you’ll need cvs, Java 6, and Ant. While GChisto requires Java 6, it can read GC logs from Java 1.4.2, 5, and 6. On Ubuntu run the following to make sure everything’s installed:
sudo apt-get install cvs sun-java6-jdk ant
First, you need to sign up for a Java.net account. The project doesn’t have any releases, so you need to have an account so you can checkout CVS. Click here to register for an account. Once you’ve registered, we need to checkout the source code. We’ll install it into a directory just under our home directory:
cd ~
cvs -d :pserver:myusername@cvs.dev.java.net:/cvs login
cvs -z9 -d :pserver:myusername@cvs.dev.java.net:/cvs checkout gchisto
Enable verbose GC logging in your java app.
This all depends on your particular application, but you need to add the following java command line options to your application startup:
-Xloggc:before-gc.out -verbose:gc -XX:+PrintGCTimeStamps -XX:+PrintGCDetails
This will create a logfile named before-gc.out in the directory from which you start your application that contains all of your GC information. For illustration purposes, let’s assume you make some GC tuning optimizations, and you want to compare before and after. Before starting the app after making your changes, change the before-gc.out to after-gc.out in the above command line options.
Using GChisto
Now, we just need to run the appropriately named ant target ‘run’:
cd gchisto
ant run
If that doesn’t work, try prepending the JAVA_HOME variable to ant like so:
JAVA_HOME=/path/to/java6/dir ant run
Once ant does it’s thing, you should be presented with the GChisto GUI. Let’s
load our logs into it. You should be presented with the “Trace Management”
tab, if not, select it. Now let’s load some traces (logs). Make sure that
“HotSpot GC Log” is selected from the dropdown box at the lower left corner,
and click the “Add” button. Browse to the location of before-gc.out, and load
it. Repeat the exact same process for after-gc.out. When done, you should have
a window that looks similar to this:  Now, let’s start doing some digging around. The first
place to visit is the “GC Pause Stats” tab. No pretty graphs right away, but
once you understand the numbers being presented to you on the “All GC Stats”
page, you will know what the graphs are telling you on the other tabs. First,
since we are comparing two files from the same application, place a checkmark
in the box “Comparison” in the lower left hand corner. Let’s explain what
these numbers are. First, the rows are diveded into these sections:
Now, let’s start doing some digging around. The first
place to visit is the “GC Pause Stats” tab. No pretty graphs right away, but
once you understand the numbers being presented to you on the “All GC Stats”
page, you will know what the graphs are telling you on the other tabs. First,
since we are comparing two files from the same application, place a checkmark
in the box “Comparison” in the lower left hand corner. Let’s explain what
these numbers are. First, the rows are diveded into these sections:
- All: Totals for all types of GC’s listed below.
- Young GC: Metrics concerning the Eden/New/Young generation of heap.
- Full GC: Metrics concerning any Full GC’s. If you care about response time in your application, avoid these at all costs. For us, even one full GC is regarded as a tuning failure.
- Initial Mark: Metrics concerning the Initial Mark phase of the CMS collector on the Old/Tenured generation of heap. With CMS, this is a ‘stop-the-world’ phase, meaning the entire application is paused for the duration of this phase. In all the cases that I have worked with, this pause is usually very quick, usually faster than GC'ing Eden. Keep an eye on this, but there’s a good chance you won’t have to tune around this one.
Remark: Metrics concerning Remark phase of the CMS collector on the Old/Tenured generation of heap. With CMS, this is a stop-the-world collection phase, meaning that the entire application is stopped during this phase - you want this to be as quick as possible. For our application, it’s the primary focus of our tuning. Each section has three rows:
File : before-gc.out: Metrics from our first file.
- File : after-gc.out: Metrics from our second file.
[Empty]: Comparison statistics. This line shows you the difference between this trace and the first trace in the list. Finally, the breakdown on the columns is as follows:
Num: Total number of occurrences.
- Num (%): Gives you the percent of occurrences - i.e, Young GC’s are > 99% of all GC’s.
- Total GC (sec): Number of seconds total spent in this GC type for the life of the VM.
- Total GC (%): Percentage of time spent on this type of GC.
- Overhead(%): Thanks to the author, Tony Printezis for clearing this one up. Overhead percentage is the percentage of total runtime in seconds (as defined by the last line of the logfile) that is spent in ‘stop-the-world’ garbage collection. Obviously, the lower the better.
- Avg (ms): The average in milliseconds each GC of this type took. This is a very important metric.
- Sigma (ms): The standard deviation between the GC’s. Smaller is better.
- Min(ms): The fastest GC of this type in milliseconds.
- Max(ms): The longest GC of this type in milliseconds. To me, this is the most important metric.
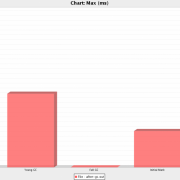
Now that you know what these numbers mean, go ahead and click around the
various subtabs under the “GC Pause Stats” tab. My personal favorites are
“Chart:Max (ms)” and “Chart: Avg (ms)”. Next, we’ll examine the “GC Pause
Distribution” tab. Everything here is pretty well self explanatory. Instead of
examining every type of GC at once, I usually deselect everything except for
one type of GC, and compare those two. Your “Young GC” distrubution should
normally be a very steep bell curve, like so:
 Personally, I don’t use the
distribution tab much. I check it for anomalies, but that’s about it. Now,
onto the “GC Timeline” tab. The “GC Timeline” tab has the same type of layout
as the previous tab, but this one presents to you the frequency and length of
each type of GC over the life of the VM. The one thing that I don’t like about
this graph is that it doesn’t display a time and date along the X axis, it
displays the number of seconds since VM startup. I’ve requested a feature that
will convert the lifetime in seconds to a real date/time stamp if you
optionally supply the VM startup time on trace file load. Hopefully the devs
will implement that one. Anyways, the timeline is very good at showing you if
your GC’s are getting longer or more frequent as time goes on. Here’s what the
Young GC timeline looks like for me:
Personally, I don’t use the
distribution tab much. I check it for anomalies, but that’s about it. Now,
onto the “GC Timeline” tab. The “GC Timeline” tab has the same type of layout
as the previous tab, but this one presents to you the frequency and length of
each type of GC over the life of the VM. The one thing that I don’t like about
this graph is that it doesn’t display a time and date along the X axis, it
displays the number of seconds since VM startup. I’ve requested a feature that
will convert the lifetime in seconds to a real date/time stamp if you
optionally supply the VM startup time on trace file load. Hopefully the devs
will implement that one. Anyways, the timeline is very good at showing you if
your GC’s are getting longer or more frequent as time goes on. Here’s what the
Young GC timeline looks like for me:  Now, most of the charting in GChisto is provided by
JFreeChart, so you get quite a bit of
built in functionality here. The best feature is the ability to drill down on
any chart. Simply left click and drag to form a rectangle on any existing
chart. When you release the mouse, the chart will zoom into the subset you
just gave it. To zoom back out, right click the chart, select “Auto
Range->Both Axes”. While you’re at it, dig around the right-click menu. In the
properties, you can change colors, axis titles, about anything else you can
think of. Another very handy feature is the ability to save any chart as a PNG
file. This helps when showing the metrics to people that don’t have GChisto
installed and available. I hope this introduction gives you some insight into
the power of GChisto. It is definitely going to become permanent in my toolbox
of GC utilities.
VisualGC is still my
favorite real-time GC monitoring solution, but GChisto is now my favorite
historical reporting tool, taking the place of PrintGCStats.
Now, most of the charting in GChisto is provided by
JFreeChart, so you get quite a bit of
built in functionality here. The best feature is the ability to drill down on
any chart. Simply left click and drag to form a rectangle on any existing
chart. When you release the mouse, the chart will zoom into the subset you
just gave it. To zoom back out, right click the chart, select “Auto
Range->Both Axes”. While you’re at it, dig around the right-click menu. In the
properties, you can change colors, axis titles, about anything else you can
think of. Another very handy feature is the ability to save any chart as a PNG
file. This helps when showing the metrics to people that don’t have GChisto
installed and available. I hope this introduction gives you some insight into
the power of GChisto. It is definitely going to become permanent in my toolbox
of GC utilities.
VisualGC is still my
favorite real-time GC monitoring solution, but GChisto is now my favorite
historical reporting tool, taking the place of PrintGCStats.
Solaris 10 HowTo Guides on sun.com
Just saw that Sun has posted a Solaris 10 HowTo guides section on their website. Looks like some good stuff: ZFS, SMF, DTrace, Containers, Live Upgrades, and more are covered.
VirtualBox 2.0 Quick Impressions
I’m not new to the virtualization scene, but I’m no expert either – I’ve been using VMWare Workstation since 1.0, VMWare Server since 1.0, and Xen since around 2.0. Well, I needed a Windows XP install on my laptop, and decided it would be a good time to see how VirtualBox compared. VirtualBox 2.0 was just released (changelog), so I went with the bleeding edge. Read on for my quick review of Virtualbox 2.0. My laptop was running Ubuntu Hardy, but your experience is likely to be the same no matter the distro you prefer.
Installation
Not much to say here. I clicked a link on the download page, GDebi popped up, and I installed the deb. Can’t get much easier!
Guest OS Installation
Anyone familiar with VMWare workstation should feel right at home here. Fire up the gui, click ‘New’, create a new Windows XP guest machine. I accepted the defaults of 192MB RAM and 10GB disk. Now, it’s been a really long time since I’ve installed Windows XP, but I swear that the installation went faster from within VirtualBox than natively. No metrics to back that up, just a gut feeling.
Networking
Worked out of the box. I accepted the default configuration of NAT through the host. Immediately I ran Windows Update after installation, and went to bed. The next day, everything had worked as it should have.
Performance
The changelog states that numerous performance improvements have been made since 1.0, but since I don’t have past experience, I can’t speak to how much better it performs. I can tell you that running Windows XP as a guest under Virtualbox 2.0 did not feel any faster, nor any slower that running Windows XP as a guest under VMWare Workstation on the same laptop. While installing SP3 for Windows XP in the guest, I noticed fairly significant host responsiveness degradation. However, my laptop still has a PATA drive in it, and my XP VM was using the “hard disk as a file” method instead of a dedicated partition. My hunch is that support for NCQ and dedicated partitions helps this quite a bit. Also, when using the XP VM under normal conditions that didn’t write to the disk so extensively, the host machine was still very responsive.
Hardware Support
Below is the list of what I’ve tested under my XP VM:
- USB: I’ll get to this eventually, but I don’t need it yet.
- Sound: Worked flawlessly.
- CD/DVD Drive: No problems here either.
Verdict
VirtualBox is an impressive product. Consider me a convert from VMWare Workstation, VirtualBox does everything I need it to and more, and the cost of zero is something VMWare Workstation can’t begin to compete with!
Set It and Forget It: Tether Your Windows Mobile 6 Phone to Linux
I have a love/hate relationship with my phone - an HTC PPC6800. I can’t live without it - I can check my work email from anywhere, and surf the web. While I’ve tried many PDA’s through the years, none of them have stuck, because I got tired of lugging them around. I always have my phone with me, so therefore my smartphone has made me much more organized. My wife loves it because I can remember all the upcoming appointments. Yet, I hate it. It’s UI is horrible. It locks up and needs rebooted, and I feel dirty using a M$ product. Well, I found one more reason to like it. I can tether my Ubuntu laptop to my phone and get Internet access from just about anywhere. This howto is for Ubuntu, but it should work for any distro that uses bluez-utils. Note that I briefly tried to get my laptop tethered via USB, but I found several comments that it wouldn’t work without a custom kernel module. Bluetooth is easier, works out of the box, and is much cooler besides ;-) First things first, let’s install the prerequisites:
sudo apt-get install bluez-utils bluetooth bluez-gnome bluez-hcidump
Next, enable the bluetooth applet in Gnome. Navigate to “System->Preferences->BlueTooth Preferences”. On the “Devices” tab, click “Other devices can connect”. Now we need to pair your phone to your PC. From your phone, click Start->Settings. Click on the Connections tab, and click the Bluetooth icon. Click “Add new device…” and choose the entry for your computer from the list. You will be asked for a passcode and when you enter it on your phone, the bluetooth applet will pop up saying that your phone is trying to connect. Click on the ballon and enter the same passcode. Congratulations, you have paired your phone to your PC! Now, let’s find the hardware address of your phone:
sudo hcitool scan
Document the 12 digit hex address somewhere, we’ll need it later. Now, open up /etc/default/bluetooth in your favorite text editor. Find the line that states:
PAND_ENABLED=0
and change the zero to a one like so:
PAND_ENABLED=1
Next, find the line which looks like:
PAND_OPTIONS=""
and change that to:
PAND_OPTIONS="--persist --connect XX:XX:XX:XX:XX:XX --role=PANU \
--devup /etc/bluetooth/pan/dev-up --devdown /etc/bluetooth/pan/dev-down"
changing the XX’s to the hardware address of your phone. Now, let’s run the following to create the scripts we need:
sudo sh -c
'mkdir -p /etc/bluetooth/pan && \ echo "iface bnep0 inet dhcp" >>
/etc/network/interfaces && \ for i in up down; do touch
/etc/bluetooth/pan/dev-$i chmod 755 /etc/bluetooth/pan/dev-$i echo
"#!/bin/bash" > /etc/bluetooth/pan/dev-$i echo "/sbin/if$i bnep0" >>
/etc/bluetooth/pan/dev-$i done && \ /etc/init.d/networking restart && \
/etc/init.d/bluetooth restart'Finally, on your phone click Start->Programs->Internet Sharing. Select “Bluetooth PAN” on the PC Connection drop-down, and select the appropriate WAN Network Connection. One more note before you’re off and surfing the ‘net on your tethered phone: your bluetooth connection can’t be managed by NetworkManager because bluez-utils doesn’t make use of DBUS. So, in order to use your bluetooth connection, right click on your Network Manager icon, and select “Enable Networking” to disable NetworkManager. When you’re done, right click and reselect “Enable Networking” to switch things back. Okay, that’s out of the way. Click on “Connect” on your phone. As your phone is connecting, your Linux box will see your phone, and connect to it. Once the connection is established, your Linux box will get a DHCP-assigned IP from your phone. To verify all this, run the following command:
/sbin/ifconfig bnep0
You should see the interface, and see that it’s been assigned an IP. After you have the address, you can freely browse the Internet. To disconnect, simply click “Disconnect” on your phone. Don’t forget to re-enable networking via NetworkManager. Props go out to the following places in helping me determine how to do this in the first place:
- InfoSec812’s post in the Ubuntu forums
- The bluez-utils howto
- The pand manpage, because I always RTFM ;-) Enjoy! Stay tuned for a post on how to sync your WM6 phone to Linux.
Profiling Your Java 1.4.2 Memory Heap
New Java 6 devs and admins get all the fun. New toys, better performance, more auto-tuning – yet you get stuck supporting a legacy java app that you can’t upgrade past 1.4.2. Well, provided you have a more recent 1.4.2 JDK, you can use jhat too!
The key is to have your app do a heap dump when sending it the QUIT signal. Append this option to your java options on startup of your application:
-XX:+HeapDumpOnCtrlBreak
Now, start your app, and let it run for awhile. There is no overhead to running with this option, however do note that your app will freeze for awhile when you send it the magic signal as it creates a heap dump. Once your app has ran for awhile, and your caches are loaded or your leak has leaked, send the java process the QUIT signal. On Windows, this is done by doing a CTRL+C at the console. On Linux & Solaris, you can send the java process the QUIT signal either by doing a CTRL+C, or finding the PID of the process and sending the signal to it. Assume a PID of 12345:
kill -3 12345
Upon sending the process the signal, you’ll see something similar to this get printed to stdout:
Dumping heap to java_pid12345.hprof.1220646896001 ... Heap dump file created [533206498 bytes in 22.836 secs]
Here you see it took my laptop about 22 seconds to dump a heap of a little over 512MB.
So now, you have the heap. You either need to have Java 6 available, or transfer the heap dump over to a computer that does. Also note you need quite a bit of RAM to run JHAT. Since JHAT loads the other VM’s heap, you need the size of your heap dump plus some working room - I recommend heapsize + 512MB. Now, if I have a 512MB heap dump, and give it another 512MB, here’s what my JHAT command line looks like:
$JAVA6_HOME/bin/jhat -J-mx1g java_pid12345.hprof.1220646896001
You’ll see output like the following (this takes a while to load):
Reading from java_pid12345.hprof.1220646896001... Dump file created Fri Sep 05 15:34:56 CDT 2008 Snapshot read, resolving... Resolving 12662545 objects... Chasing references, expect 2532 dots.... Eliminating duplicate references............ Snapshot resolved. Started HTTP server on port 7000 Server is ready.
Now, open up a web browser to http://localhost:7000/, and find that memory leak!!!
Use GMail as an SMTP Relay Using SSMTP
On some of your home workstations, and especially on a laptop, setting up a full-blown SMTP server such as Postfix, Sendmail, or Exim might be overkill. Follow the jump to learn how to setup the lightweight ssmtp to relay all outbound mail through your GMail account by using Gmail as a smarthost. SSMTP is meant to be a no-frills, secure, and lightweight replacement for a full-blown MTA. Personally, I feel it’s best use is on a laptop where you’re moving around between networks a lot, and need to send outbound emails from cron or other shell scripts. By setting up SSMTP, it doesn’t matter where you are, sending mail will be sent out over encrypted SMTP to Google’s gmail servers. After handing it off, Google’s servers do all the routing for you. Setting up SSMTP is quick and easy - let’s get to it. On Ubuntu, run:
\# sudo apt-get install ssmtp mailxNow, we just need to configure SSMTP. Open up /etc/ssmtp/ssmtp.conf in your favorite editor, and add or update the following lines:
\#The following line redirects mail to root to your gmail account root=myemail@gmail.com
mailhub=smtp.gmail.com:587
UseSTARTTLS=yes
UseTLS=yes
AuthUser=myemail@gmail.com
AuthPass=mypasswordThat’s it! Now, let’s try testing it:
$ echo "This is a test message." | mailx -s 'Test Message' myemail@gmail.comYou should now be all setup and ready to go!
Quick and Painless Ubuntu Speed Tweaks
As far as performance, Ubuntu 8.04 isn’t bad out of the box. However, the developers had to make some performance sacrifices in order to remain compatible with older machines. If you have a newer machine with at least 512MB RAM, enabling these tweaks will significantly speed up your Ubuntu experience. There’s a lot of copy and paste blog posts out there on Feisty, and a lot of so-called tweaks that I feel are unnecessary. Where I aim to differentiate this post is to specialize on tweaks relevant to 8.04, and to cover only the 80/20 rule of performance – 20% of the work done tweaking will net you 80% of the speed boost. There’s a lot more that you can tweak, but it really won’t net you that much gain. Here’s what I use on all my desktop Ubuntu installs.
1. Start your services in parallel at boot.
Instead of starting one service at a time, let’s start them all as fast as possible, and in parallel. This will actually slow down older, single core machines, but faster P4’s, and multiple core CPU machines will benefit from this. Run this command, and reboot:
sudo perl -i -pe 's/CONCURRENCY=none/CONCURRENCY=shell/' /etc/init.d/rc
2. Utilize preload to speed up application startup time.
If you have some extra RAM, look into preload. From the preload website:
preload is an adaptive readahead daemon. It monitors applications that users run, and by analyzing this data, predicts what applications users might run, and fetches those binaries and their dependencies into memory for faster startup times.
You can read all about how it does it and how it can be tweaked on this article on techthrob.com, but you can just “set it and forget it” and it will be fine. Run the following command:
sudo apt-get install preload
and bask in the glory of the speed boost!
3. Swappiness != Happiness.
If you have enough RAM, you shouldn’t ever need to use swap. Heck, RAM is cheap. If you’re short on RAM, stop reading this article and go buy some.
My best guess is that the Ubuntu devs do this for folks running on older systems with less RAM, but it doesn’t help any on systems with 512MB or more RAM. Swappiness basically controls the tendency of the kernel to page memory out to disk. You can read the gory details over at kerneltrap.org, or just run the following commands:
sudo sysctl vm.swappiness=5
sudo su -c 'echo vm.swappiness=5 >> /etc/sysctl.conf'
4. Profile your boot process.
This has got to be one of the most undocumented features in Ubunutu. I found many sites saying to “do this”, but none said why. A forum post on the Ubuntu site pointed me in the right direction.
Basically, the second thing to start during boot in Ubuntu is readahead. The init script is at /etc/rcS.d/S01readahead. It preloads all the libs that you might need during bootup. The list of files that this service will load is contained in /etc/readahead/boot (and /etc/readahead/desktop). It’s good to do this once, then repeat it after you do a major upgrade such as a dist-upgrade, or significantly change your startup services. Please note that it will slow the boot process during the profile step, as it’s recording what’s needed at boot time. Your next boot will be much faster.
To start profiling, do the following on bootup:
- At the bootup menu (GRUB), select your default kernel. You may need to press ESC to see this menu.
- Press e for edit.
- Choose the first line (it should start with “kernel”). Press e again.
- Move to the end of the line, then add the word profile. Press enter.
- Press b to boot.
- Let the system boot to the login screen, and wait for all disk activity to stop. Remember, during this one bootup, you’ve told Ubuntu to keep track of all disk activity going on, in order to build that list. Don’t be surprised if it’s significantly slower than your ordinary bootups – that’s why it’s not activated by default, remember?
- Reboot your system, and enjoy the results.
5. Don’t start unneeded services.
Don’t start services that you don’t need or use. They eat up RAM, and consume CPU cycles. The purpose of this post isn’t to define all these services (that may make a nice post in and of itself), it’s to show you how to turn them off.
If you like command line/curses interfaces:
sudo apt-get install sysv-rc-conf && sudo sysv-rc-conf
If you want a GUI:
sudo apt-get install bum && gksudo bum
I run a lot of stuff on my laptop, so I couldn’t disable too many things, but here’s what I did disable: rsync, nfs-kernel-server, apmd, apport, and avahi-daemon.
Noteables
Many of the other posts out there will have you tweaking your own kernel. While I’m not against this (it makes you learn a lot about how Linux works), doing it for performance reasons isn’t the way to go. You might speed things up a bit, but if you’re that much of a tweaker, look into Gentoo Linux.
Another item left off the list is the tweaking of the ext3 mount options in /etc/fstab. For the most part, Hardy comes out of the box with decent mount options. The one possible exception is the use of noatime. noatime disables the logging of the last access time of the files, and if you’re absolutely sure there’s nothing you use that needs this, then you are okay to replace any occurrence of ‘relatime’ with ‘noatime’ in /etc/fstab. However, if you look at the man page for mount, you’ll see that relatime is a nice compromise between full access time logging and none at all.
Well, that about wraps it up. If you have your own tweaks you’d like to share, post it in the comments!
Mozilla Weave Setup on CentOS 5.2
Mozilla Weave is a project from Mozilla Labs that aims to keep all of your browser data synced between all of your PC’s. The now defunct Google Browser Sync used to do this, as does Foxmarks. Although Weave is still in it’s infancy, it’s been very promising thus far. However, many of the users of Mozilla’s own Weave server complain that the service is very slow. The beauty of Weave is that it uses the standard protocol WebDAV to sync it’s data. Why does that matter? Because our good ‘ol buddy Apache can speak WebDAV out-of-the box! Follow the jump to find out how you can setup your own server that you can sync to. In our scenario, we’ll be setting up Weave to sync to a CentOS 5.2 server running Apache 2.2. We’ll use mod_ssl to encrypt the communications - and to conserve IP’s and SSL certs, we’ll setup Weave as a subdirectory under the main SSL virtual host. However, you should be able to adapt these instructions to any Apache installation where mod_ssl and mod_dav_fs is installed and available. There’s two phases to the installation: 1. Setup of the Apache server 2. Setup of the Firefox client(s)
Setup of the Apache server
First, make sure that you have mod_ssl installed: yum install mod_ssl
Now, make sure the following lines are present in /etc/httpd/conf/httpd.conf to enable WebDAV:
LoadModule dav_module modules/mod_dav.so
LoadModule dav_fs_module modules/mod_dav_fs.so
<IfModule mod_dav_fs.c>
DAVLockDB /var/lib/dav/lockdb
</IfModule>Now, let’s setup our directory alias off of the main SSL virtual host. We’ll maintain our configuration in a separate file. Create a file named /etc/httpd/conf.d/mozilla-weave.include with this in it: Alias /weave /apps/mozilla_weave/www
<Directory /apps/mozilla_weave/www>
SSLRequireSSL
Options Indexes FollowSymLinks
AllowOverride AuthConfig Limit
Order allow,deny
Allow from all
AuthType Basic
AuthName "WebDAV Restricted"
AuthUserFile /apps/mozilla_weave/passwords
require valid-user
</Directory>
<Location /weave>
DAV On
</Location>Now, let’s get this file included in the main SSL virtualhost. On CentOS, edit the file /etc/httpd/conf.d/ssl.conf. Just before the closing VirtualHost tag, insert the include statement: include /etc/httpd/conf.d/mozilla-weave.include
Now, let’s create our directory structure (replace ‘myusername’ with whatever username you want to authenticate with): cd /apps mkdir -p mozilla_weave/www/user/myusername chown -R apache:apache mozilla_weave
Now, we’ll create our htaccess file - again replace ‘myusername’: echo “require user myusername” > mozilla_weave/www/user/myusername/.htaccess chown apache:apache mozilla_weave/www/user/myusername/.htaccess htpasswd -c mozilla_weave/passwords myusername
Finally, let’s restart Apache: /etc/init.d/httpd restart
Setup of the Firefox client(s)
First, download the latest Weave plugin from here. Go ahead and restart Firefox. It will start the Weave wizard on startup, but for now click cancel. Click the new Weave icon down in your status bar, and click on “Preferences”. Now click on the advanced tab. You need to change the Server Location field to the URL that we just set up in Apache. In my case, I used https://www.techadvise.com/weave. Now, click on the Account tab, and click the “Sign In” button. Click the “Next” button, followed by “Set Up Another Computer”. Should be self explanatory from here out - just use the same username and password we set up earlier via Apache. The latest versions of Weave require you to use SSL. Since not everyone has money to throw away, you might be using a self-signed certificate. When you do, you need to browse to https://www.yourdomain.com/ and jump through all the hoops to autmatically accept the certificate before it will work in Weave. If you don’t do this, Weave will give you the error “Username / password incorrect”
One PC down, now go to all of your other machines and point them at your new WebDAV enabled directory. Then enjoy all the synchronized goodness with great performance!